Knowledge Distillation和模型压缩
Date: 2019/08/18 Categories: 工作 Survey Tags: DeepLearningInference
Knowledge Distillation
BAM! Born-Again Multi-Task Networks for Natural Language * Understanding
这篇论文是利用知识蒸馏来帮助提升模型效果的文章
- 要点:
- 利用权重系数 $$\lambda$$ 结合了多任务学习和多任务蒸馏
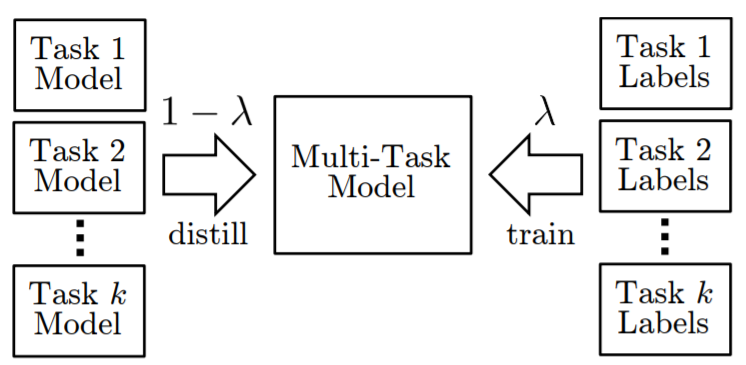 (Teacher Annealing, 教师退火)
(Teacher Annealing, 教师退火) - 上图中的模型蒸馏实际使用的多个单任务模型的输出去蒸馏一个多任务模型, 获得类似于集成学习的效果
- 利用权重系数 $$\lambda$$ 结合了多任务学习和多任务蒸馏
- 实验:
- STS, 回归任务, 没有类别分布信息可供蒸馏, 没有提升
- 蒸馏与多任务学习可互补(意料之中), single to multi比multi to multi的蒸馏结果要好, 多个teacher模型, 类似ensembling
- 要点:
Apprentice: Using Knowledge Distillation Techniques To Improve Low-Precision * Network Accuracy
- 结合了KD和量化, 思路是利用KD去做regularizer训练量化模型, 实验很丰富, 主要是resnet
Transformer to CNN: Label-scarce distillation for efficient text classification
- 文本分类场景下的蒸馏实验, 使用cnn蒸馏transformer
Quantization
一般对于int8来说可以不需要原始训练数据得到接近的准确率, 但对更低进度比如int4或binary就需要原始数据了
- Low-Precision 8-bit Integer Inference - OpenVINO * Toolkit
- 需要的cpu指令是sse4.2, av2或者avx512
- 支持的层为
- Convolution
- FullyConnected (AVX-512 only)
- ReLU
- ReLU6
- Pooling
- Eltwise
- Concat
- Resample
- iIntroducing int8 quantization for fast CPU inference using OpenVINO - Intel AI
- 从文中的表格来看,大多数网络的加速比在1到2之间, 也就不到两倍
- Quantized Transformer
- 做了量化BERT的实验, int8模型, 在小数据(数千)上准确率超过fp32, 在Squad上比fp32模型低一个点
- Optimization for BERT Inference Performance on CPU - Apache MXNet - Medium
- mxnet, int8, inference加速比1.8x, 准确率下降0.73%
Pruning
- Rethinking the Value of Network * Pruning
- 这篇文章的观点是传统的三阶段剪枝是不必要的, prune实际起到的是模型结构搜索的功能, 得到模型结构后从头训练比剪枝的效果好(有争议)
- Pruning neural networks: is it time to nip it in the * bud?
- 与上面一篇类似
-
- Deep Compression的开山作
-
- 结合了dropout和prune, 利用targeted dropout在训练阶段使得网络对剪枝不敏感
- 提供了notebook可以实践, https://github.com/sharanry/Targeted-Dropout/blob/master/Targeted-Dropout.ipynb
Conditional Computation
直接根据每一层做决策
- Efficient Inference on Deep Neural Networks by Dynamic Representations and Decision Gates
- 插入两个决策门, 然后训练时在决策门处使用hingeloss训练是否判断或移动到下一阶段
- 比较了hingeloss和交叉熵, hingeloss在early exit这种用途下更好
- 节省的flops不到50%
一般是使用强化学习的方法, 优化一个序列决策问题, 将模型执行时间(可以是node数量或者估计的执行时间)和准确率/f1都考虑进损失函数中, 比如